

xAI는 Grokipedia로 구글의 Gemini를 무너뜨리려 하고 있습니다
더 뛰어난 검색을 하기 위한 xAI의 Grokipedia
xAI는 25년 10월 27일, AI 기반 온라인 백과사전, Grokipedia를 공개했습니다. 일론 머스크는 Grokipedia가 위키피디아의 편향성을 제거하기 위해 만들어졌다고 이야기하지만, 진짜 목적은 따로 있다고 생각합니다. xAI에게 Grokipedia는 구글의 Gemini를 이기기 위한 발판입니다.
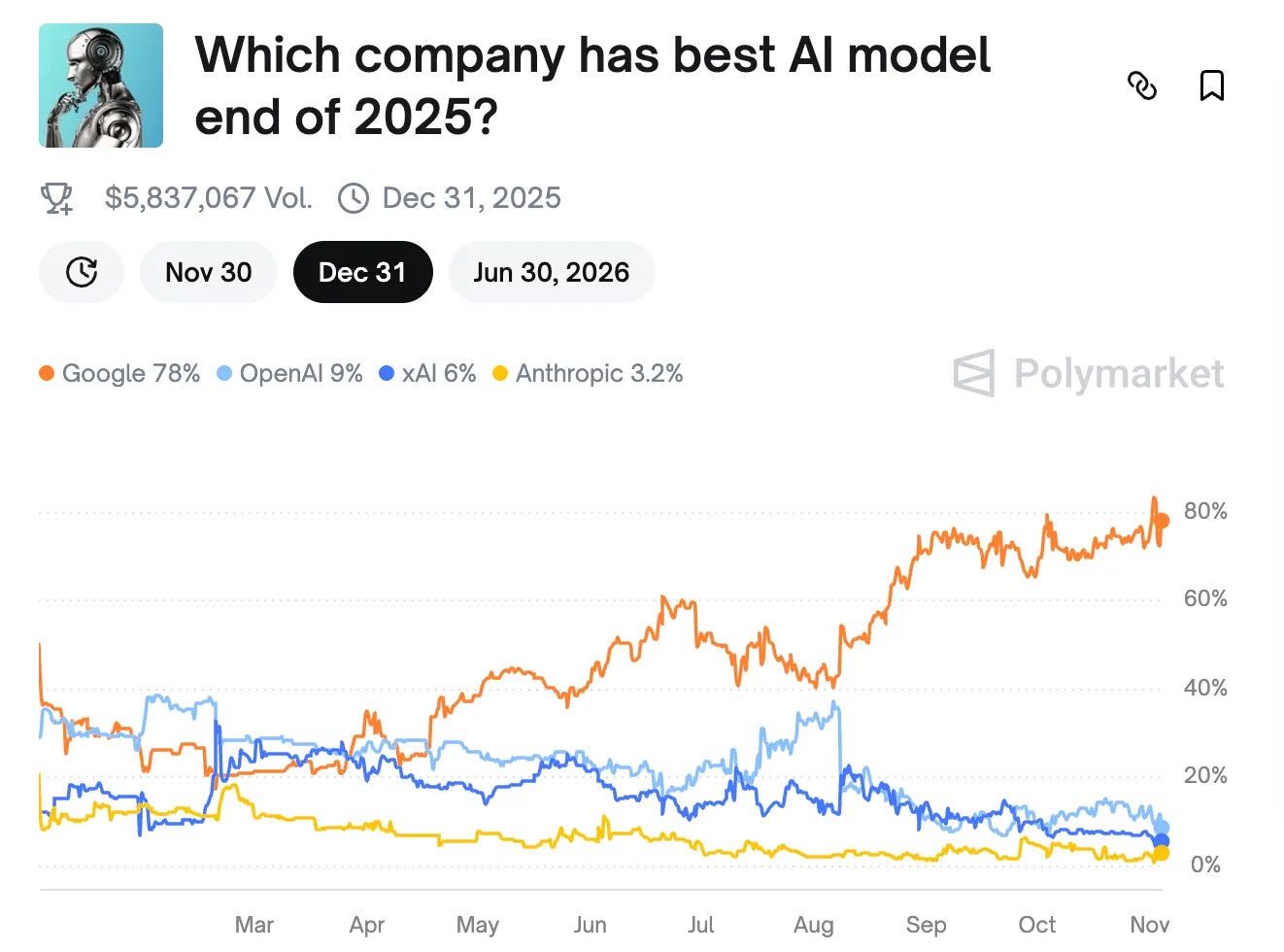
지금 AI 업계를 보면 구글 Gemini의 위상이 엄청나게 높아지고 있습니다. 예측 시장 플랫폼에서 2025년 최고 AI가 Gemini일 가능성이 80%에 육박하고, LLM 모델의 성능을 평가하는 LMArena에서 Gemini는 텍스트, 비전, 이미지, 영상 생성 등 거의 모든 분야에서 1위를 차지하고 있습니다. 반면 xAI의 Grok은 대부분 분야에서 고전 중입니다.
그런데, Grok이 순위권에 든 분야가 딱 하나가 있습니다. 당연히 구글이 1위를 차지할 것으로 생각이 드는 검색 분야에서 Grok은 1위를 차지하고 있습니다.
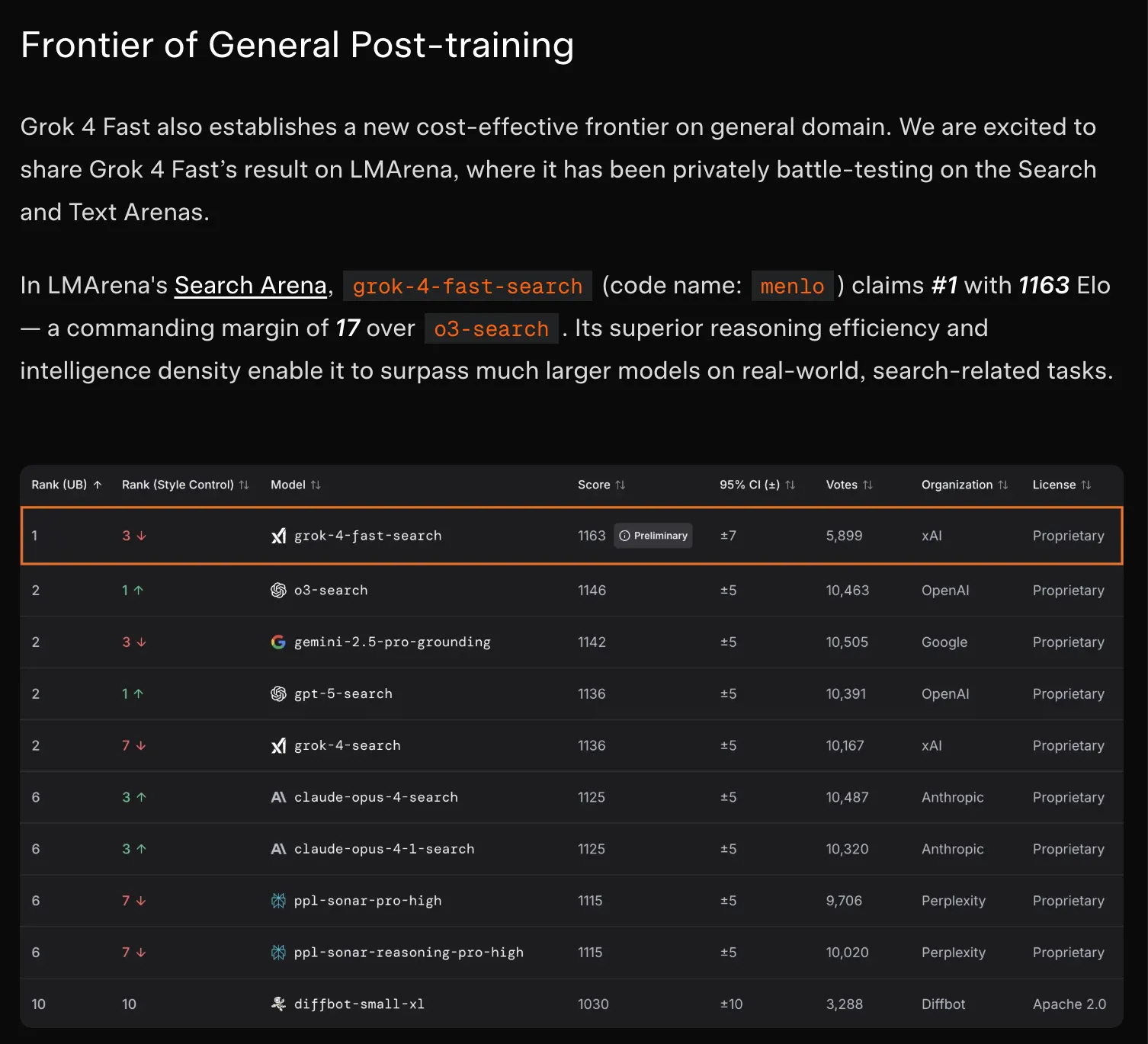
2025년 9월 출시된 Grok 4 Fast 모델은 (1) 비용 감소에 집중하고 (2) 오로지 검색에만 집중했는데, 이는 xAI가 LLM 모델의 자체 성능보다도 제대로 된 AI 검색이 더 중요하다고 판단한 결과가 아닐까 하고 생각합니다.
GPT-3.5 이후 LLM 모델의 성능이 비약적으로 발전한 건 Chain-of-Thought(CoT)라 불리는 Reasoning AI의 등장이었습니다. AI가 최종 답을 내놓기 전에 생각하게 함으로써 LLM 모델의 성능을 비약적으로 높일 수 있게 되었습니다. 그리고 이 Reasoning AI는 인터넷 검색과 결합해, AI가 생각하는 과정에서 웹 검색을 하는 Deep Research 모델이 현재까지 가장 성능이 좋은 SOTA 모델입니다.
이처럼 LLM 모델에서 모델 성능과 더불어, 검색의 중요도가 엄청나게 높아지고 있습니다. OpenAI 마저도 구글 검색을 이용해 ChatGPT를 훈련하고, ChatGPT가 답변을 내놓게 할 정도로 AI 경쟁에서 검색의 중요성이 높아지고 있고, 검색이 AI 경쟁의 승부처가 되었다고 과언이 아닙니다.
그런데 검색을 잘 하기가 쉽지 않습니다. 구글 마저도 모든 콘텐츠를 보고 인덱싱할 능력을 가지고 있지 않습니다. 되려, 구글은 콘텐츠 제작자에게 ‘메타 데이터’라는 이름으로 좋은 콘텐츠인지를 알려달라고 요청할 정도로 좋은 검색을 하는 것은 어렵습니다.
그렇다면 좋은 콘텐츠를 미리 만들어 두어서 LLM이 필요할 때 찾아서 쓰게 만들면 어떨까요? 매번 검색하는 구글보다 더 좋은 검색이 가능하지 않을까요? 저는 이게 Grokipedia라고 생각합니다.
Grokipedia처럼 LLM 모델에게 전달할 웹 검색 자료를 미리 문서화해두면 여러 이점이 있습니다.
매번 같은 문서를 이용하기에 KV-cache를 활용, 더 낮은 비용으로 더 많은 Context Window를 사용할 수 있습니다.
문서를 API로 전달할 수 있기에 LLM에게 더 적합한 형태로 전달할 수 있습니다.
여러 링크를 찾아 비교 분석하지 않아도 되기 때문에 비용을 낮추고, 추론에 리소스를 집중할 수 있습니다.
Grokipedia는 xAI가 구글보다 더 좋은 검색을 하여, Grok이 더 좋은 답변을 하는데 이용될 것입니다.
Grokipedia는 xAI의 검색 우위를 만드는 핵심 인프라가 될 것이고, 나아가 구글의 Gemini를 무너뜨릴지도 모릅니다.
Grokipedia는 텍스트 정보를 LLM이 연산하는 수단인 K-V, 즉 벡터화 시킨 것을 저장해서 공개했다는 것이 중요한 Contribution인것 같습니다.
이 연산 부분이 실제로 모든 LLM에서 매번 이루어지는 작업이며, Context Length에 무시못할 부분을 차자히는게 맞고 연산량에 큰 Bottle neck이 되는것도 맞아서 “연산 속도” 또는 “재연산의 불필요성”의 측면에서 좋은 효율을 가져와줄 수 있어보이네요.
Grok이 검색을 더 잘하는 이유는 Browser를 더 적극적으로 활용하도록 설계된 것이 이유입니다. 실제로 Gemini는 Deep Research를 켜지 않는 이상 Browsing을 그렇게까지 활용하지 않더군요.
하지만 Google은 이미 이미지, 장표, 영상 등의 이해에서 좋은 성능을 보인다는 것을 증명했습니다. 이는 우리가 아무 이미지나 넣어도 잘 해석하는 Gemini를 보면 알 수 있어보입니다. 또 Youtube에서 이미 여러 실시간 번역, Summarize등의 기능을 확인할 수 있기 때문에 Google이 못해서 안하는 것은 아닌것 같습니다.
어디까지나 이건 개발의 방향성 차이같습니다.
구글은 기능은 있지만 수익성과 실용성을 위해 그런 기능을 활용하지 않는 것이고, Grok은 또 다른 전략을 택한다고 보는게 맞다고 볼 수 있습니다.
때문에 Grokipedia가 Grok이 검색을 더 잘할 것이다 그래서 Gemini를 이길 수 있다로 이어지는 점은 불분명해 보입니다.
검색을 하는 것으로만 한정하여 Task를 쪼개어 보자면 아마 3가지 단계가 필요할 것 같습니다.
1. 사용자의 의도가 무엇인지 = 검색을 어떤 단어로 할 것인지
2. 검색된 결과를 어떻게 해석할 것인지
3. 검색된 결과를 어떻게 User에게 보여줄 것인지
기술적 관점에서 Grokipedia는 1번 단계에서 검색을 하고 나온 Text정보를 Vector화 하는 부분을 미리 해둔(Prefill) 서비스입니다.
이것은 결국 1번 단계 “수행 시간을 단축”하는 기능입니다. 그리고 결국 “Text정보를 Vector화”하는 것은 아마도 Grok의 성능이 upper bound이겠죠.
나머지 2번 3번도 매우 중요한 과제이기 때문에 이 부분을 어떻게 처리하느냐에 따라달렸습니다.
grok이 앞으로 Grokipedia에서 자신의 검색을 수행한다면 수익성, 효율성 측면에선 좋아질 수 있습니다만 이게 검색시장에서 결국 승자가 되기엔 Kick이 없습니다.
정보는 매번 새로 생겨나니까요. 그리고 결국 Grok은 또 다시 Google에 가야합니다.
물론 이렇게 노하우를 쌓으며 앞지를 방법을 모색할 수도 있구요 :)
그래도 이런걸 서비스화 한것은 개인 개발자입장에선 반가운 소식일 수 있겠네요 ㅎㅎ