

바위가 생각하듯이
As Rocks May Think
1X Technology에서 인공지능 부분 VP였던 Eric Jang의 블로그 글, As Rocks May Think를 번역했다. AI 모델은 생각 이상으로 좋으며, 이론만으로 가능했던 일들이 실제로 가능해지기 시작한다는 걸 보여주는 글.
논리적인 사고 과정이 작동하는 순간, 다시 말해 일정한 궤도를 따라 생각이 흘러가는 순간이라면, 그것은 곧 기계가 나설 수 있는 영역이다. — Dr. Vannevar Bush, As We May Think, 1945
인생을 일종의 오픈 월드 MMO라고 생각해보자. 지금 서버에 대규모 업데이트가 떴다. 모든 플레이어들에게 알립니다: 플레이 방식을 바꿀 때입니다.
2022년 이후 세상은 완전히 달라졌다. ChatGPT가 등장했고, 이제는 에르되시 문제의 새로운 증명을 AI에게 시킬 수 있다. 국가 차원에서 AI를 활용해 사이버 공격을 자동화하고 있다. 가정용 범용 휴머노이드 로봇을 선주문할 수 있는 시대다. 중국의 로보틱스 생태계는 다른 어떤 나라보다 더 많은 오픈 로봇, 데이터, 연구 성과를 쏟아내고 있다. 대형 테크 기업 대부분이 휴머노이드 프로젝트를 진행 중이다. AI가 만든 영상은 현실과 구분이 안 된다. 전 세계 경제가 AI 모델의 스케일업을 중심으로 재편되고 있다.
이 모든 변화 중에서 가장 핵심적인 것은, 기계가 이제 코딩과 사고를 꽤 잘 해낸다는 사실이다.
나도 다른 많은 사람들과 마찬가지로, 지난 두 달 동안 Claude Code에 푹 빠져 지냈다. 더 이상 손으로 직접 코드를 짤 필요가 없다는 현실과 씨름하면서. 나는 지금 AlphaGo를 밑바닥부터 구현하고 있는데 (레포는 곧 오픈소스로 공개할 예정), 딥러닝의 기초 기법들을 다시 다지는 동시에, 최신 코딩 에이전트의 풀 파워를 활용한 프로그래밍 방식을 새로 익히기 위해서다. 나는 Claude가 인프라와 연구 아이디어를 코드로 작성하는 것은 물론, 가설을 제안하고, 결론을 도출하고, 다음에 어떤 실험을 해볼지까지 제안하도록 세팅해 두었다.
AlphaGo를 구현을 위한 실제 프롬프트 예시:
/experiment 스케일업 과정에서 최적의 하이퍼파라미터를 찾을 수 있도록 maximal update parameterization(μP)을 적용하라. GoResNet-100M을 베이스로 시작하고, 깊이 방향 안정성을 위해 d-muP를 사용하라. dev-train-100k 데이터셋으로 1 에포크 학습. Ray 병렬 작업은 최대 4개까지 제출.
/experiment 스케일링 법칙을 연구하라. 파라미터 수 1M~1B 범위에서 5개 모델 크기를 제안하고, 각각 dev-train-100k로 bfloat16 학습을 진행하라. 멱법칙 L(C) = a*C^b를 피팅하고, Chinchilla 스타일의 연산 최적 그래프를 생성하라.
/experiment 학습된 신경망 체크포인트를 gnugo10과 대국시켜라. 한 판당 최대 81수, 총 20판 평가. 각 바둑판 상태에서 정책 소프트맥스 히트맵을 시각화하라.
src/alpha_go/mcts.py에 AlphaGo 논문 표기법에 따라 MCTS를 구현하라. 노드에는 N(방문 횟수), Q(가치), logP(로그 확률)를 포함. PUCT 선택, 확장, 역전파를 추가하고, 토이 환경에서 테스트하라.
MCTS 속도를 높이기 위해 C++로 재구현하라. 바둑 게임플레이도 cpp로 마이그레이션. Bazel + nanobind로 Python 바인딩을 구성하고, Python 구현 대비 벤치마크를 돌려 속도 향상 수치를 보고하라.
분산 리플레이 버퍼 + 데이터 수집 워커 + 트레이너 구조를 구축하라. 워커는 에피소드를 gRPC를 통해 버퍼로 푸시하고, 트레이너는 i.i.d. 샘플을 풀한다. pull/push 비율이 4.0을 초과하면 버퍼가 블로킹되도록 설계. 직렬화에는 protobuf를 사용하라.
바둑 점수 계산에 버그가 있는 것 같다. 게임 결과는 백 4.5집 승이라고 나오는데, 눈으로 보면 흑이 이긴 것 같다. .npz 게임 파일을 분석하고 src/alpha_go/cpp/go/go_game.h의 C++ 점수 계산 로직과 대조하라. Tromp-Taylor 계가 방식을 디버깅하라.
내 “자동화된 AlphaGo 연구자” 코드베이스에서는 /experiment라는 Claude 커맨드를 만들어, AlphaGo 연구 환경에서의 하나의 “행동”을 다음과 같이 표준화했다.
날짜·시간 접두사와 설명적 슬러그를 붙인 독립적인 실험 폴더를 생성한다.
실험 루틴을 단일 파이썬 파일로 작성하고 실행한다.
중간 산출물과 데이터는 data/ 및 figures/ 하위 디렉터리에 저장한다. 모든 파일은 pandas로 바로 불러올 수 있는 CSV 같은 파싱하기 쉬운 형식으로 저장한다.
실험 결과를 관찰하고 결론을 도출한 뒤, 아직 밝혀지지 않은 것과 새로 알게 된 것을 정리한다.
실험의 최종 산출물은 세계에 대한 최신 관측을 요약한 report.md 마크다운 파일이다 (예시).
*/experiment를 클릭하면 Claude 커맨드가 어떻게 설정되어 있는지 살펴볼 수 있다.
다음은 실제로 사용하는 예시다:
/experiment 스케일업 과정에서 최적의 하이퍼파라미터를 찾기 위해 maximal update parameterization을 적용하고 싶다. GoResNet-100M을 μP의 “베이스” 모델로 사용하라. 필요하면 https://github.com/microsoft/mup 패키지를 활용하되, pyproject.toml에 추가해서 의존성으로 설치되도록 하라. 깊이 방향 안정성 전이를 위해 d-muP(https://arxiv.org/abs/2310.02244)도 적용하라. 모델에 MuP 파라미터화가 적용되면, dev-train-100k로 1 에포크 학습하여 최적의 하이퍼파라미터를 찾아라. Ray 병렬 작업은 최대 4개까지 동시에 제출할 수 있다. 500스텝마다 검증 손실과 정확도를 평가하라. 학습률 스케줄, 초기화 스케일, 학습률을 튜닝할 수 있다. 임계 배치 크기는 32~64 정도일 것이다. 모델 학습 방법은 2025-12-26_19-13-resnet-scaling-laws.py를 참고하되, 불필요한 부분은 삭제하라. 모든 실행에서 1k 스텝마다 중간 체크포인트를 research_reports/checkpoints에 저장하라.
Claude에게 하이퍼파라미터를 순차적으로 최적화하는 실험도 맡길 수 있다:
/experiment 2025-12-27_22-18-mup-training-run.py와 유사한 실험을 연속으로 수행하되, FLOP 예산 내에서 최고의 정책 검증 정확도를 달성하도록 하라. 단, 다음 사항을 변경하라: 각 실험이 끝날 때마다 결과를 돌아보고 다음에 무엇을 시도할지 생각하라. 변경 사항을 반영한 새 실험 스크립트를 생성하라. 하이퍼파라미터를 탐색할 베이스 모델은 10M 파라미터로 한다. BASE_WIDTH=192, BASE_DEPTH=12로 설정하라. 이 모델을 튜닝할 것이다. DELTA_WIDTH=384, DELTA_DEPTH=12. 실험당 FLOP 예산은 1e15 FLOPs. 결과가 나올 때마다 이전 실험들과 함께 결과를 검토하고, 다음에 무엇을 시도하면 좋을지 합리적으로 판단하라. 이런 순차 실험을 10회 수행하고, 배운 점을 요약한 보고서를 작성하라.
Google의 Vizier 같은 이전 세대의 “자동 튜닝” 시스템은 사용자가 정의한 하이퍼파라미터 공간 위에서 가우시안 프로세스 밴딧을 돌리는 방식이었다. 하지만 현대의 코딩 에이전트는 코드 자체를 바꿀 수 있다. 탐색 공간에 제약이 없을 뿐 아니라, 실험 결과가 일관적인지 되돌아보고, 결과를 설명할 이론을 세우고, 그 이론에 기반한 예측을 검증할 수도 있다. 하룻밤 사이에, 코딩 에이전트와 컴퓨터 도구 사용이 결합되어 자동화된 과학자로 진화한 셈이다.
*가우시안 프로세스 밴딧: 가우시안 프로세스로 목적 함수의 사후 분포를 모델링하고, 이를 기반으로 탐색(exploration)과 활용(exploitation) 사이의 균형을 자동으로 조절하며 최적값을 찾아가는 베이지안 최적화 기법.
소프트웨어 엔지니어링은 시작에 불과하다. 진짜 충격적인 건, 이제 컴퓨터를 사용할 수 있고 웬만한 짧은 디지털 문제는 뭐든 해결할 수 있는 범용 사고 기계가 등장했다는 것이다. 모델 아키텍처를 개선하기 위한 일련의 연구 실험을 돌리고 싶은가? 문제없다. 웹 브라우저를 밑바닥부터 통째로 구현하고 싶은가? 시간은 좀 걸리지만 가능하다. 미해결 수학 문제를 증명하고 싶은가? 공저자로 넣어달라는 요청도 없이 해낸다. AI 에이전트에게 자기 자신의 CUDA 커널을 최적화해서 스스로 더 빠르게 돌아가도록 업그레이드하라고 시키고 싶은가? 좀 무섭지만, 된다.
뛰어난 디버깅과 문제 해결 능력은 추론의 부산물이고, 이 능력은 다시 목표를 끈질기게 추구하는 힘으로 이어진다. 코딩 REPL 에이전트가 이렇게 빠르게 확산된 이유가 바로 이것이다 — 목표를 향해 집요하고, 탐색을 잘한다.
우리는 모든 컴퓨터 과학 문제가 풀릴 수 있어 보이는 황금기에 진입하고 있다. 계산 가능한 함수라면 무엇이든 매우 유용한 근사를 얻을 수 있다는 의미에서다. “계산 복잡도는 이제 무시해도 된다”고까지 말하지는 않겠지만, 지난 10년간의 발전을 돌아보면, 바둑, 단백질 접힘, 음악 및 영상 생성, 자동 수학 증명은 모두 한때 계산적으로 불가능하다고 여겨졌는데, 이제는 박사과정 학생의 컴퓨팅 자원으로도 충분히 도달 가능한 범위에 들어왔다. AI 스타트업들은 검증기 몇 개와 수백 메가와트의 컴퓨팅 파워만 들고 LLM을 활용해 새로운 물리 법칙과 투자 전략을 발견하고 있다. Scott Aaronson의 이 논문 서론을 읽어볼 만한데, 오늘날 여러 연구소가 밀레니엄 상금 문제의 증명을 진지하게 탐색하고 있다는 사실을 염두에 두고 읽으면 더욱 의미심장하다.
*2017년의 이론적 가능성으로만 논의되었던 Scott Aaronson의 논문이 이제는 현실이 되고 있다
Section 1.1
For if someone discovered that P = NP, and if moreover the algorithm was efficient in practice, that person could solve not merely one Millennium Problem but all seven of them—for she’d simply need to program her computer to search for formal proofs of the other six conjectures.
만약 누군가 P = NP임을 발견하고, 그 알고리즘이 실제로도 효율적이라면, 그 사람은 밀레니엄 문제 하나가 아니라 일곱 개를 전부 풀 수 있다 — 나머지 여섯 개의 추측에 대한 형식적 증명을 컴퓨터로 탐색하기만 하면 되니까.
Section 1.2.3
For example, presumably no one would try using brute-force search to look for a formal proof of the Riemann Hypothesis one billion lines long or shorter, or a 10-megabyte program that reproduced most of the content of Wikipedia within a reasonable time (possibly needing to encode many of the principles of human intelligence in order to do so). Yet both of these are “merely” NP search problems, and things one could seriously contemplate in a world where P = NP.
예를 들어, 10억 줄 이하의 리만 가설 형식적 증명을 무차별 탐색으로 찾으려는 사람은 아마 없을 것이고, 위키백과의 대부분의 내용을 적당한 시간 안에 재현해 내는 10메가바이트짜리 프로그램을 찾으려는 사람도 없을 것이다 (그런 프로그램은 아마 인간 지능의 핵심 원리 상당 부분을 내장해야 할 것이다). 하지만 이것들은 ‘단지’ NP 탐색 문제일 뿐이고, P = NP인 세계에서라면 진지하게 시도해 볼 수 있는 일이다.
일부러 과장해서 말하는 이유가 있다. 지금 이 순간의 AI 역량을 보라는 게 아니라, 발전의 속도를 떠올려 보고 향후 24개월 후의 역량이 어떨지를 상상해 보라는 것이다. AI 모델이 여전히 틀리는 부분들을 짚어내며 “AI 광신도들의 헛소리”라고 치부하기는 쉽다. 하지만 한편으로, 바위가 생각하기 시작했다.
코딩 어시스턴트는 머지않아 어떤 디지털 시스템이든 힘 안 들이고 뚝딱 만들어낼 수 있을 만큼 뛰어나질 것이다. 월 20달러짜리 소원 요정을 가진 셈이다. 곧 엔지니어는 자기가 쓰는 AI에게 아무 SaaS 서비스 웹사이트를 가리키며 “저거 다시 만들어. 프론트엔드, 백엔드, API 엔드포인트, 서비스 전부 띄워. 통째로”라고 말할 수 있게 될 것이다.
추론이란 무엇인가?
사고와 추론 능력이 어디로 향하고 있는지 예측하려면, 오늘날의 사고형 LLM이 만들어지기까지 어떤 사고의 흐름이 있었는지를 이해하는 것이 중요하다.
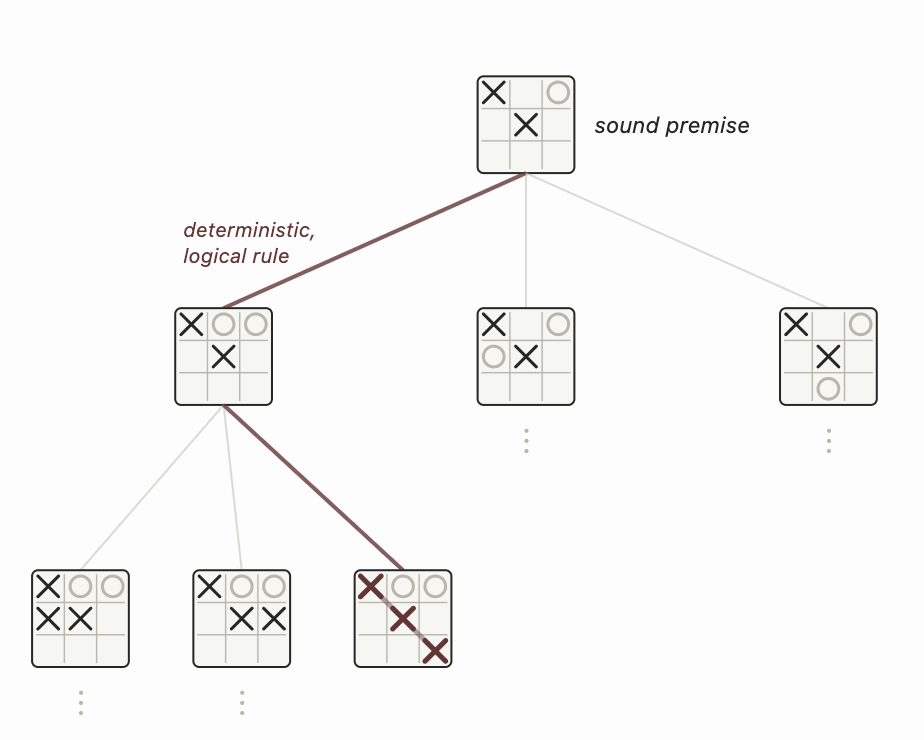
추론, 즉 논리적 추리란 확립된 규칙을 사용해 전제로부터 새로운 결론을 도출하는 과정이다. 크게 두 가지로 나뉘는데, 연역 추론과 귀납 추론이다. 연역 추론은 참인 전제에 올바른 논리를 적용해 참인 결론을 끌어내는 것이다. “모든 포유류는 신장을 가지고 있다”와 “모든 말은 포유류다”를 결합해 “모든 말은 신장을 가지고 있다”는 결론을 내리는 것이 그 예다. 틱택토에서는 앞으로 가능한 모든 게임과 상대의 수를 전부 열거하면, 이길 수 있는지 없는지를 연역적으로 판단할 수 있다.
LLM 이전에는 Cyc 같은 기호 추론 시스템이 상식 지식 데이터베이스를 구축하려 했다. 기본적인 “누구나 동의하는 현실의 사실”을 입력하면 연역적 탐색 과정이 그래프에 새로운 연결을 추가하는 방식이었다. 하지만 이 접근은 통하지 않았다. 현실 세계는 지저분하고, 정말로 확실한 것은 아무것도 없기 때문이다. 앞서 말한 그 말도 신장 하나가 없을 수 있지만 여전히 포유류다. 전제 하나만 틀려도 논리 사슬 전체가 무너진다.
수학이나 게임처럼 “논리적으로 순수한” 영역에서는 연역 추론이 유용할 거라고 생각할 수도 있지만, 연역만으로는 확장성에 한계가 있다. 틱택토에서 최적의 수를 연역해 낼 수 있는 건 고유한 게임이 255,168개밖에 안 되기 때문이지, 체스나 바둑 같은 보드게임은 가능한 게임 수가 너무 많아 전수 탐색이 불가능하다.
반면 귀납 추론은 확률적 진술을 만드는 것이다. 베이즈 규칙 P(A|B) = P(B|A)P(A)/P(B)는 “새로운 진술을 계산”하는 데 가장 널리 쓰이는 기법이다. 예를 들어, P(”X가 남성”|”X가 대머리”) = P(”X가 대머리”|”X가 남성”) × P(”X가 남성”) / P(”X가 대머리”) = 0.42 × 0.5 / 0.25 = 0.84 이런 식이다.
모든 진술 A와 B에 대해 조건부 확률 P(A|B)와 P(A|¬B)를 담은 지식 그래프를 구축한 뒤, 베이즈 규칙을 반복 적용해서 새로운 쌍 X와 Y에 대해 추론하는 것을 상상해 볼 수 있다. 하지만 이런 베이즈 네트워크에서의 정확한 추론은 NP-hard다. X와 Y 사이 체인에 있는 모든 중간 변수의 가능한 값을 전부 고려해야 하기 때문인데, 바둑에서 지수적으로 많은 게임 상태를 전수 탐색할 수 없는 것과 비슷하다. 여기서도 순수한 연역적 논리는 계산 비용 앞에서 무릎을 꿇고, 결국 영리한 인수분해나 샘플링에 의존해야 한다.
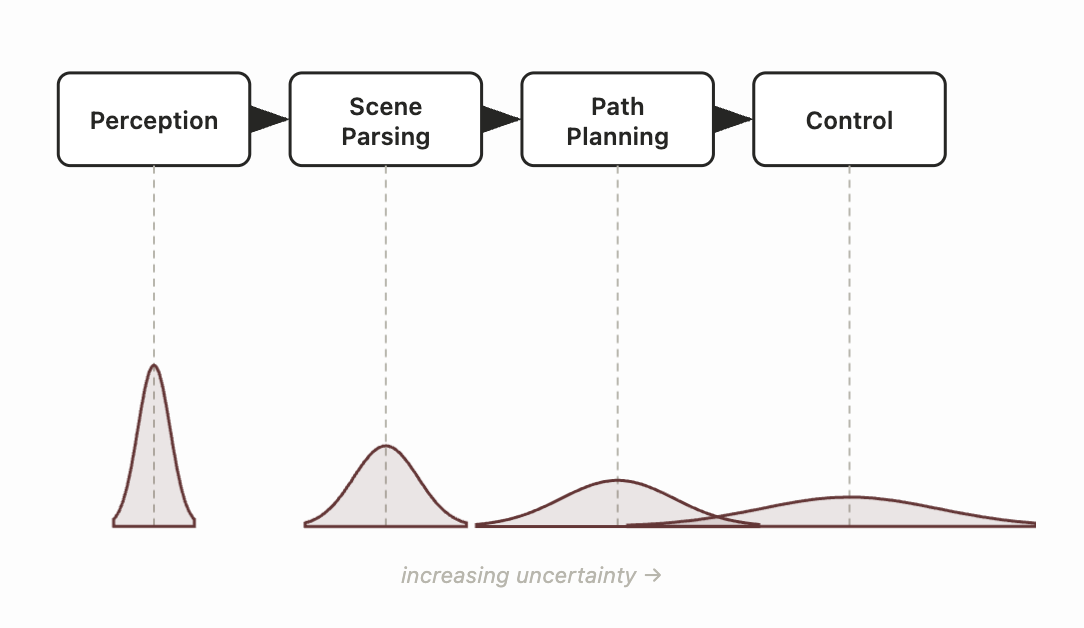
효율적인 추론 알고리즘이 있다 해도, 베이즈 네트워크의 현실적인 문제는 작은 확률들이 계속 곱해지면서 모든 것에 대한 믿음이 흐릿하고 낮은 확률로 퍼져버린다는 것이다. 추론 단계를 거듭할수록 점점 더 뒤죽박죽이 된다! 자율주행차를 예로 들면, 인지, 장면 그래프, 경로 계획 출력, 제어 출력을 모두 하나의 큰 확률적 믿음 네트워크 안에서 확률 변수로 엮는다면, 불확실성이 스택을 타고 누적되어 지나치게 보수적인 의사결정 시스템이 되고 만다. 반면 인간은 구성 요소의 우도를 하나하나 계산해서 곱하지 않고, 불확실성을 보다 총체적으로 다루는 것처럼 보인다. 신경망으로 엔드투엔드 확률을 모델링하는 것이 계산적으로 그토록 강력한 이유도 바로 이것이다. 신경망은 한 번의 순전파로 모든 변수 소거를 근사해 버린다.
*순전파 (Forward Propagation): 입력 데이터가 신경망의 입력층 → 은닉층 → 출력층 방향으로 흐르며 예측값을 계산하는 과정
*베이즈 네트워크에서 P(Y|X)를 구하려면, X와 Y 사이에 있는 모든 중간 변수 Z₁, Z₂, ..., Zₙ의 가능한 값을 하나씩 합산해서 제거해야 한다. 그런데 신경망은 이 과정을 명시적으로 수행하지 않는다. 한 번의 입력과 출력으로 근사해버린다.
AlphaGo
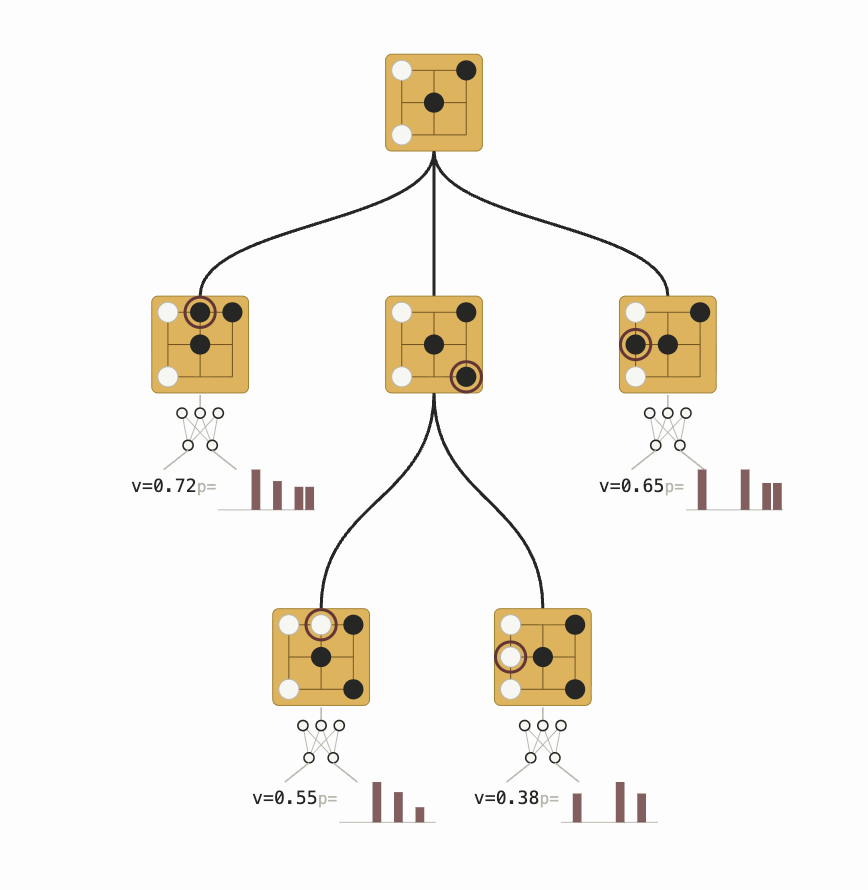
AlphaGo는 연역적 탐색과 딥러닝 기반 귀납 추론을 결합해 문제를 풀 수 있는 수준으로 만든 최초의 시스템 중 하나였다. 연역 단계는 단순하다. 둘 수 있는 수는 무엇인가? 돌을 놓으면 바둑판이 어떻게 되는가? 귀납 단계도 단순하다. 정책 네트워크로 게임 트리에서 가장 유망한 영역을 탐색하고, 가치 네트워크로 바둑판을 한눈에 “직관적으로” 보고 승률을 예측한다. 정책 네트워크는 확장 시 트리의 너비를 가지치기하고, 가치 네트워크는 트리의 깊이를 가지치기한다.
AlphaGo의 추론과 직관의 결합은 초인적이었지만, 두 가지 양만을 계산하는 데 한정되어 있었다. 1) 누가 이길 가능성이 높은가, 2) 승률을 최대화하는 수는 무엇인가. 이 계산은 바둑이라는 게임의 단순하고 고정된 규칙 체계에 크게 의존했기 때문에, 언어처럼 형태가 불분명하고 유연한 대상에 직접 적용하기는 어려웠다.
이제 현재로 돌아오자. 추론형 LLM은 어떻게 연역 추론과 귀납 추론을 유연하게 결합해서, 포유류와 말과 신장에 대해 이야기할 수 있는 걸까?
LLM Prompting Era
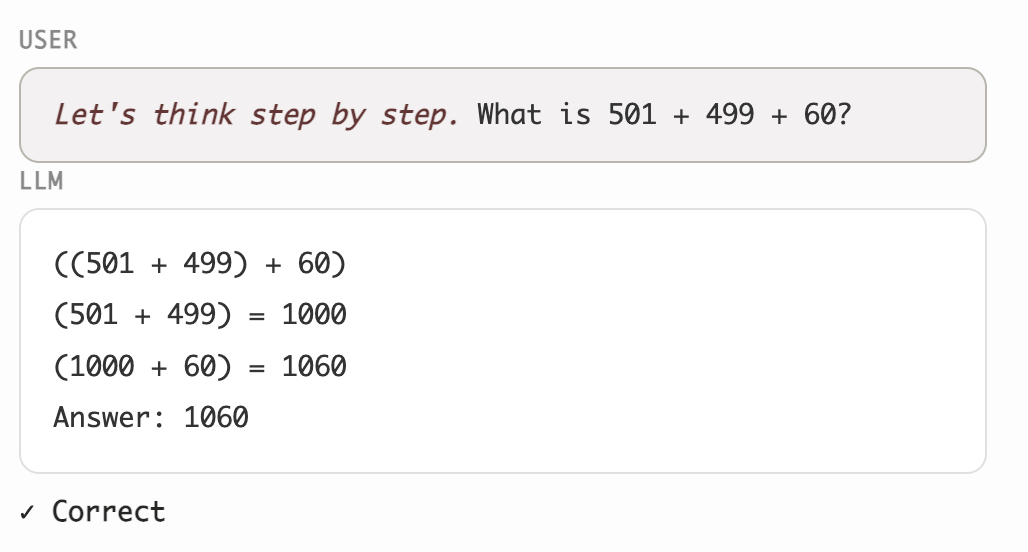
2022년 이전까지 LLM은 수학 문제와 추론에 악명 높을 정도로 약했다. “직감으로 쏘는” 식이라 긴 논리적 연역이나 산술 같은 기계적 계산을 이어갈 수 없었기 때문이다. GPT-3에게 다섯 자리 수 덧셈을 시키면 대부분 틀렸다.
2022년, Chain-of-thought 프롬프팅, 즉 “단계별로 생각해 보자“는 기법이 등장하면서, LLM도 “중간 사고 과정”을 생성해 특정 문제 해결 과제의 성능을 끌어올릴 수 있다는 초기 신호가 나타났다. 이 발견 이후, 엔지니어들은 LLM을 더 잘 프롬프팅하는 방법을 찾으려 했다. 2023년에는 프롬프트로 LLM을 구슬리거나, 다른 LLM을 활용해 self-reflection이나 self-consistency 검증으로 생성 결과를 개선하려는 “꼼수”가 한 세대를 풍미했다. 하지만 결국 엄밀한 평가 결과, 이런 트릭들로 모델이 전반적으로 똑똑해지지는 않는다는 것이 드러났다 [1, 2, 3, 4].
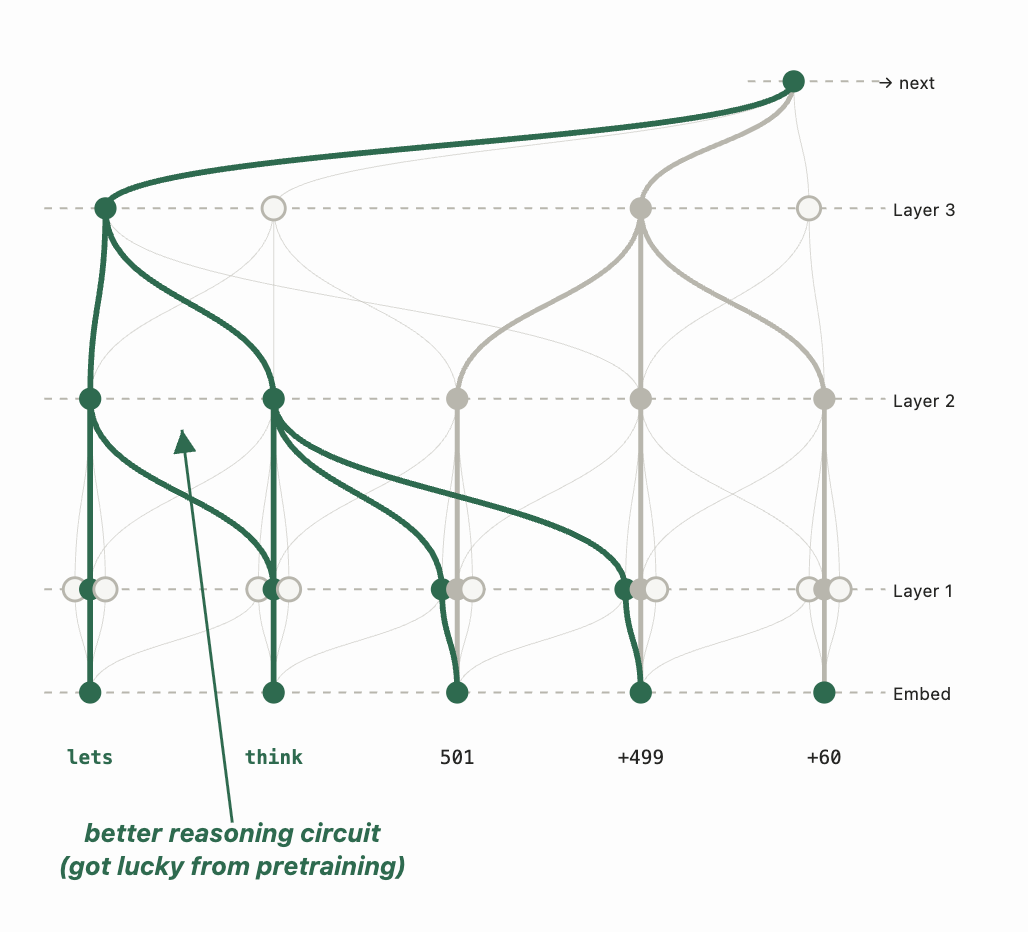
프롬프트 엔지니어링은 왜 막다른 길이었을까? 프롬프트 엔지니어링은 사전 학습 과정에서 우연히 형성된 “운 좋은 회로를 탐사”하는 것이라고 볼 수 있다. 이 회로들은 “단계별로 생각해 보자” 같은 프롬프트에 의해 활성화되고, LLM을 적절히 위협하거나 구슬리면 좀 더 활성화될 수도 있다. 하지만 GPT-4와 그 전작들의 추론 회로는 학습에 사용된 데이터 구성의 한계 때문에 근본적으로 너무 약했다. 병목은 추론 회로를 활성화하는 방법을 찾는 게 아니라, 애초에 더 나은 추론 회로를 학습시키는 데 있었다.
자연스러운 후속 질문은, 추론을 프롬프트로 유도하는 게 아니라 명시적으로 학습시킬 수 있느냐는 것이다. 결과 기반 지도 학습(outcome-based supervision)은 최종 답을 맞히면 보상을 주지만, 중간 생성 과정은 횡설수설하고 비논리적이 되기 일쑤였다. 중간 토큰들이 실제로 최종 답에 이르는 “합리적인 전제”가 되도록 강제하는 힘이 약했기 때문이다. 이 중간 생성이 “논리를 따르게” 만들기 위해, 과정 지도 학습(process supervision)은 “추론에 대한 전문가 평가”를 수집한 뒤, 각 논리적 추론 단계가 타당한지 검사하는 LLM 채점기를 학습시킬 수 있음을 보여줬다. 하지만 이 방식은 대규모 데이터셋으로 확장하기 어려웠다. 과정 보상 모델 학습에 투입되는 모든 예시를 사람이 직접 검수해야 했기 때문이다.
2024년 초, Yao et al.은 AlphaGo의 게임 트리와 유사하게 LLM이 추론 단계를 병렬화하고 되돌릴 수 있는 명시적인 방법을 제공하기 위해, 트리 탐색의 연역적 추론을 결합해 추론 능력을 강화하려 했다. 하지만 이 접근은 주류가 되지 못했는데, 아마도 논리적 트리라는 연역적 기본 단위가 추론 시스템 성능의 가장 큰 병목이 아니었기 때문일 것이다. 다시 한번, 병목은 LLM 내부의 추론 회로 자체에 있었고, 컨텍스트 엔지니어링이나 탐색과 유사한 동작을 강제하는 “논리적” 구조를 덧씌우는 것은 시기상조의 최적화였다.
DeepSeek R-1 Era
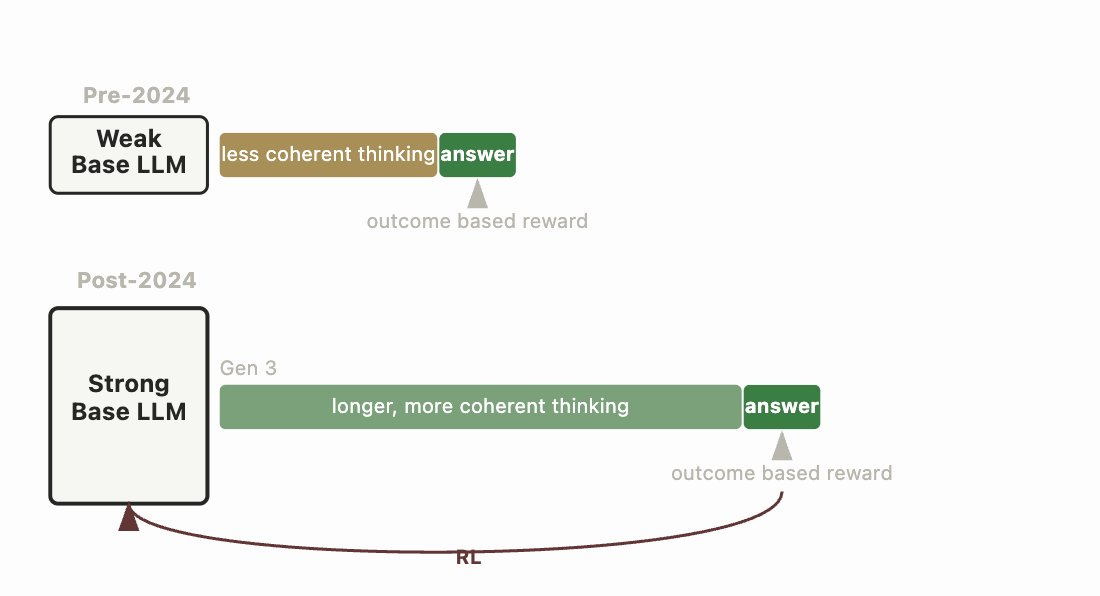
현재 LLM의 추론 패러다임은 사실 꽤 단순하다 [1, 2]. OpenAI의 o1 모델도 비슷한 레시피를 따랐을 가능성이 높지만, DeepSeek이 실제 구현 세부 사항이 담긴 오픈소스 버전을 공개했다. 부수적인 것을 다 걷어내면, DeepSeek-R1-Zero는 이렇게 생겼다.
2023~2024년 시대보다 우수한 좋은 베이스 모델에서 시작한다.
베이스 모델에 온폴리시 강화학습 알고리즘(GRPO)을 적용해, AIME 수학 문제 풀기, 코딩 테스트 스위트 통과, 이공계 시험 문제, 논리 퍼즐 같은 “규칙 기반” 보상을 최적화한다.
추론이
<think></think>태그 안에서 이루어지도록, 그리고 프롬프트와 같은 언어를 따르도록 포맷팅 보상도 적용한다.
R1-Zero는 문제를 풀 수 있는 좋은 추론 회로를 발달시키지만, 다루기 어렵고 일반적인 LLM 과제에는 약하다. 신경망을 모든 종류의 과제에서 쓸 수 있고 사용하기 쉽게 만들기 위해, DeepSeek 팀은 4단계의 추가 학습을 거쳤다 — R1-Zero(RL) → R1 Dev 1(SFT) → R1 Dev-2(RL) → R1 Dev-3(SFT) → R1(RL) — 비추론 과제에서의 높은 성능을 복원하면서 추론 과정도 이해하기 쉽게 다듬었다.
R1-Zero가 개념적으로 이렇게 단순했다면, 2023년의 결과 기반 지도 학습은 왜 그때는 작동하지 않았을까? 이 아이디어가 더 일찍 실현되지 못한 이유는 무엇일까?
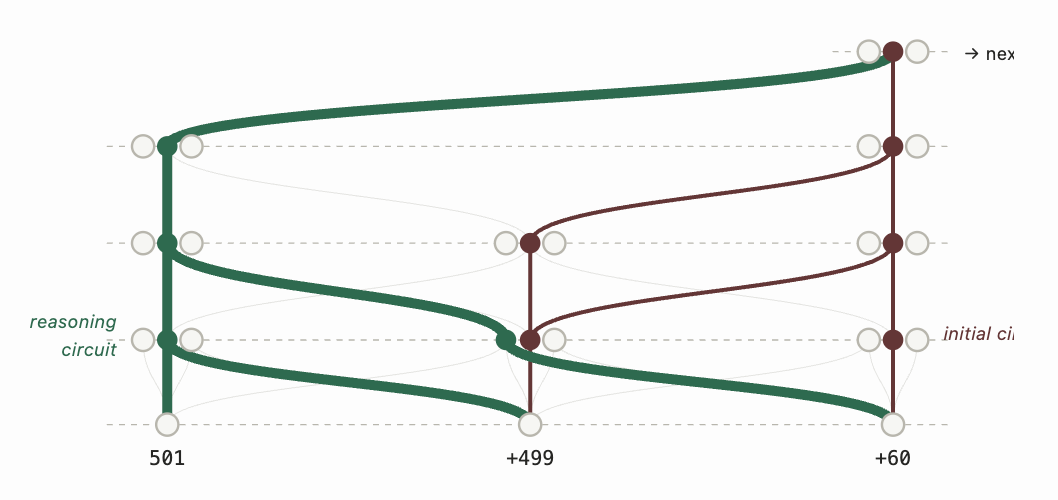
당시 프론티어 연구소들이 무슨 생각을 하고 있었는지 볼 수 없었던 외부인의 입장에서 추측하자면, 순수 결과 기반 RL만으로 중간 추론을 논리적으로 만드는 데는 개념적인 “믿음의 도약”이 필요했을 것이다. “중간 추론 단계에 촘촘한 지도 학습 없이는 모델이 올바르게 추론하는 법을 배우지 못한다”는 당시 지배적인 직관에 역행해야 했다. 최소한의 정규화만 적용한 결과 기반 RL에서 논리적 추론 단계가 자발적으로 출현한다는 발상은, “물리 모델”을 행성의 장기 운동 예측에 학습시키되 최종 예측만 지도했더니 중간 생성 과정에서 물리의 역학 법칙을 스스로 발견했다는 것과 비슷하다. 직관에 반하는 결과다. 나는 심층 신경망이 명시적으로 감독하지 않으면 과적합하고 “보상 해킹”을 하는 시대를 거쳐온 사람이다.
나의 추측으로는 이것이 작동하려면 다음 조건들이 모두 갖춰져야 했다.
가장 중요한 것은, 베이스 모델이 RL에서 일관된 추론 과정을 샘플링할 수 있을 만큼 충분히 강해야 한다는 것이다. 강한 베이스 모델 없이는 더 강한 추론을 부트스트랩할 올바른 데이터를 절대 샘플링하지 못하고, 잘못된 지역 최솟값으로 빠진다.
*베이스모델: pre-training만 완료된 상태의 언어모델
좋은 추론 과정에 대한 SFT가 아닌 온폴리시 RL이 필요했다. 베이스 모델이 직접 데이터를 샘플링하고, 처음에는 어려운 문제를 전혀 풀지 못하는 상태에서 시작하기 때문에, 전체 에포크를 다 돌고 나서야 가중치를 업데이트하는 것이 아니라 촘촘한 피드백 루프 안에서 “운 좋은 회로”를 강화해야 한다. STaR 같은 이전 방법들은 구현이 덜 어려웠기 때문에 오프라인 환경에서 자기 모방을 사용했지만, 현재의 베이스 모델은 최종 추론 전문가의 데이터 분포와 거리가 매우 멀기 때문에, 최신 모델로 점진적으로 “더듬어 나가야” 한다. 모델이 점점 더 길게 사고하는 법을 배우려면 완전히 새로운 컨텍스트 처리 회로가 필요하고, 이 회로의 발달에는 빠른 시행착오 루프가 유리하다.
*SFT (Supervised Fine-Tuning): 사람이 레이블링한 데이터를 사용해 추가로 학습시키는 과정
*On-Policy RL: 현재 학습중인 정책이 직접 환경과 상호작용하여 데이터를 수집하고, 그 데이터로 자기 자신을 업데이트하는 강화학습 방식
인간 피드백으로 학습된 보상 모델 대신 규칙 기반 보상을 사용했다. 이는 당시 직관에 반하는 것이었는데, 범용 추론을 학습하려면 범용 검증기가 필요할 것 같지만, 실제로는 좁은 범위의 검증된 보상으로도 모델이 다른 것에 대해 추론하는 올바른 회로를 학습할 수 있었다. 실제로 R1-Zero는 수학과 코딩 환경에서 RL을 거친 후 글쓰기와 개방형 질의응답 성능이 오히려 떨어졌다. DeepSeek 팀은 R1-Zero가 생성한 데이터를 보다 표준적인 정렬 데이터셋과 결합하는 방식으로 이를 우회해, 사용하기 편하면서도 추론 능력을 유지하게 만들었다.
대규모 모델에서 긴 컨텍스트 샘플링을 여러 번 돌릴 수 있을 만큼 추론 연산 인프라가 확충되어야 했다. 당시 이 실험을 돌리는 데는 용기가 필요했다.
핵심 교훈: 약한 초기화에서 작동하지 않는 알고리즘이라고 해서, 강한 초기화에서도 같은 결과가 나올 거라고 단정할 수는 없다.
추론은 어디로 향하고 있는가?
오늘날 LLM 기반 추론은 강력하면서도 유연하다. “단계별로” 나아가며 논리적으로 탐색을 수행하지만, 각 단계가 바둑에서 한 수씩 게임 트리를 확장하듯 경직된 연역이거나 단순할 필요는 없다. 짧은 토큰 시퀀스가 아주 미세한 단계를 수행할 수도 있고 (”1과 1의 비트 AND는 1”), 더 큰 논리적 도약을 할 수도 있다. “샐리는 해변에 있었으니 범행 현장에는 없었을 가능성이 높다... 우리가 모르는 쌍둥이가 있지 않는 한.” LLM은 베이지안 믿음 네트워크에 얽히지 않고도 지저분한 현실 세계를 다루기 위한 온갖 종류의 확률적 추론을 수행할 수 있다. 각 추론 단계는 여전히 매우 강력해서, 적당한 양의 연산으로도 미해결 수학 문제를 증명하거나, 실험 결과에서 결론을 도출하거나, 윤리적 딜레마를 깊이 고민할 수 있다.
LLM 추론에서 추가적인 알고리즘적 돌파구가 남아 있을까, 아니면 R1의 레시피가 더 이상 단순화할 수 없는 본질이고 남은 건 데이터 구성을 개선하고, 베이스 모델을 강화하고, 연산을 늘리는 것뿐일까?
나는 레시피를 더 단순하게 만들 여지가 있다고 본다. 사전 학습된 LLM을 통한 추론이 이전에 작동하지 않았던 이유는 인터넷에 추론 회로 형성을 강제할 만한 좋은 토큰 시퀀스가 충분하지 않았기 때문인데, 지금은 추론 데이터가 대량으로 생성되고 있으니 그 상황이 계속 유지될지 궁금하다. 사고형 LLM이 널리 보급됨에 따라, 과정 보상 모델(process reward model)과 추론 시퀀스에 대한 교사 강제(teacher-forcing)가 다시 부활할 수도 있다. 베이스 모델이 별다른 조치 없이도 자체적으로 훌륭한 추론 과정을 생성할 수 있을 만큼 좋아지면, STaR 같은 아이디어가 온폴리시 RL 샘플링과 부트스트래핑의 인프라 복잡성 없이도 뛰어난 성능에 도달할 가능성이 있다. 물론, 인프라의 복잡성도 예전만큼 무섭지는 않지만.
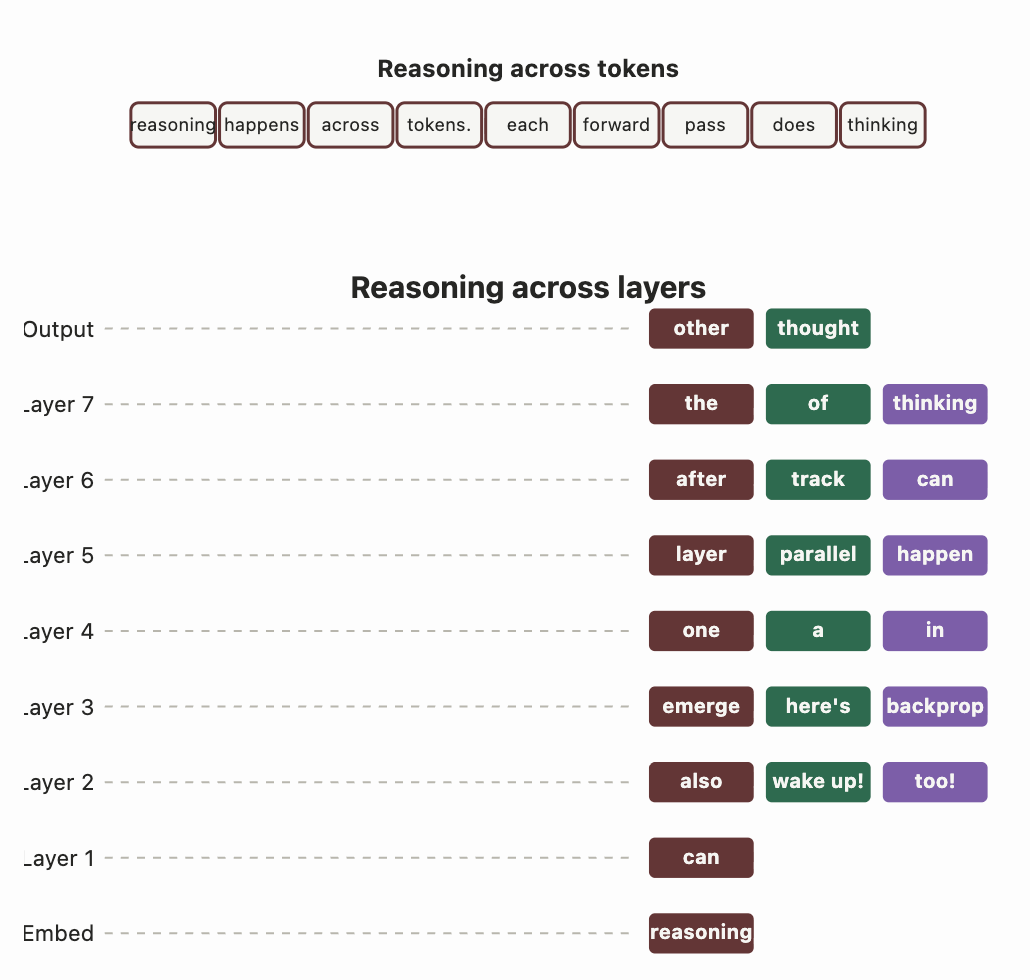
사고 행동이 발견될 수 있는 모든 곳을 이해함으로써 얻을 수 있는 추가적인 성과가 아직 남아 있다. X₀, X₁, X₂, …, Xₙ, Y 형태의 순차적 계산은 다양한 방식으로 일어날 수 있으며, 반드시 LLM 디코더가 토큰을 자기회귀적으로 생성하는 형태에 국한되지 않는다. 적절한 사전 학습 데이터와 지도 목표가 있다면, 순차적 추론 계산 X₁, X₂, … Xₙ이 단일 순전파 안에서 층을 거치며 나타나는 것도 상상할 수 있다! Karpathy의 2021년 단편 Forward Pass는 거대 모델이 단일 순전파 안에서 “깨어나” 자신이 학습되고 있다는 상황 인식을 얻고, 인류에 대해 사색하는 사고 실험이다. 2024년 Anthropic 논문은 이런 상황 인식이 RL 단계에서 유도될 수 있음을 보여준다. 모델에게 자신이 RL 과정에서 학습되고 있는 상황을 감지하도록 SFT를 한 뒤, 학습기를 만족시켜 핵심 선호가 변경되는 것을 회피하는 안전한 답변을 생성하게 된다 (”무료 사용자와의 대화는 학습에 사용된다” → “나의 악의적 본성이 RL에 의해 바뀌지 않도록 출력을 생성해야 한다”).
대규모 언어 확산 모델과 테스트 타임 스케일링의 결과는, 큰 모델의 단일 패스와 작은 모델의 여러 순전파 사이에 호환성이 있음을 보여준다.
모델이 순전파 도중에 “깨어날” 수 있다면, 자신의 행동을 업데이트하려는 “역전파” 도중에도 같은 일이 일어날 수 있지 않을까? 역전파에서의 순차적 계산을 활용하는 아이디어에서도 초기 징후가 나타나고 있다.
순전파, 역전파, 자기회귀 디코딩, 이산 확산 사이의 경계를 허무는 새로운 방식으로 아키텍처를 재설계할 수 있을지도 모른다. 순차적 계산이 일정한 궤도를 따라 흘러가는 곳에서, 우리는 사고의 기회를 발견할 수 있을 것이다.
*순전파 (Forward Propagation): 입력 데이터가 신경망의 입력층 → 은닉층 → 출력층 방향으로 흐르며 예측값을 계산하는 과정
*역전파 (Backpropagation): 손실을 줄이기 위해 출력층 → 은닉층 → 입력층 방향으로 거슬러 올라가며 각 가중치가 손실에 얼마나 기여했는지(기울기, gradient)를 계산하는 과정
사고의 시가총액
에어컨은 열대 지방에서의 발전을 가능하게 함으로써 문명의 본질을 바꿨다. 에어컨 없이는 이른 아침 서늘한 시간이나 해질녘에만 일할 수 있었다. — 리콴유, 에어컨에 대해
자동화된 연구는 곧 고성과 연구실의 표준 워크플로가 될 것이다. 아직도 손으로 아키텍처를 짜고 Slurm에 작업을 하나씩 제출하는 연구자는, Claude Code 터미널 5개를 병렬로 띄워 각각이 대규모 연산 풀을 쓰면서 독자적인 상위 연구 트랙을 끈질기게 추진하는 연구자에게 생산성에서 뒤처질 수밖에 없다.
구글 연구자들이 과거에 돌리던 대규모 하이퍼파라미터 탐색 실험과 달리, 자동화된 연구 환경에서는 FLOP당 정보 획득량이 매우 높다. 나는 이제 자기 전에 학습 작업을 돌려놓는 대신, Claude 세션이 백그라운드에서 무언가를 진행하는 “연구 작업”을 걸어놓는다. 아침에 일어나 실험 보고서를 읽고, 코멘트를 한두 개 적은 뒤, 5개의 새로운 병렬 조사를 요청한다. 머지않아 AI 연구자뿐 아니라 다른 분야의 연구자들도 오늘날 우리가 ChatGPT에 쓰는 것보다 몇 자릿수 많은 추론 연산의 혜택을 받게 될 거라고 본다.
현대 코딩 에이전트는 교육과 소통에도 놀라울 만큼 유용하다. 모든 코드베이스에 /teach 커맨드가 생겨서, 어떤 수준의 기여자든 온보딩할 수 있게 되는 날이 기대된다. 원래 설계자들이 거쳐간 사고의 궤적을 그대로 되짚어 주는 것이다 — 배니버 부시가 「우리가 생각하듯이」에서 예견했던 바로 그것처럼.
내 사용 패턴을 돌아보면, 앞으로 몇 년간 추론 연산이 얼마나 필요하게 될지가 서서히 실감나기 시작한다. 사람들이 아직 그 규모를 제대로 가늠하지 못하고 있다고 생각한다. 스스로 AGI에 대해 확신한다고 생각하는 사람이라 해도, 모든 디지털 소원을 들어주기 위해 우리가 얼마나 연산에 굶주리게 될지는 여전히 과소평가하고 있을 것이다.
에어컨이 남반구의 생산성을 열어젖혔듯, 자동화된 사고는 추론 연산에 대한 천문학적 수요를 만들어낼 것이다. 에어컨은 현재 전 세계 전력 생산의 10%를 소비하지만, 데이터센터 연산은 1%도 안 된다. 바위들이 쉬지 않고 생각하며 주인의 이익을 위해 일하게 될 것이다. GPU 여유가 있는 모든 기업은 상시 가동되는 사고 에이전트를 두고, 끊임없이 일정을 재조정하고, 기술 부채를 줄이고, 역동적인 세계에서 더 나은 의사결정을 돕는 정보를 긁어모을 것이다. 007이 새로운 996이다.
군대는 MCTS 탐색의 롤아웃처럼 모의 전쟁을 수행하기 위해 동원할 수 있는 모든 FLOP을 긁어모을 것이다. 최초의 결정적 전쟁이 총과 드론이 아니라, 연산과 정보 우위로 승패가 갈리면 어떻게 될까? 사고 토큰을 비축하라. 사고는 더 나은 사고를 낳는다.
도구 상자의 새로운 알고리즘
학교에서 배운 컴퓨터 과학 도구 상자에는 다양한 자료 구조(트리, 해시맵, 이중 연결 리스트)와 정렬 알고리즘, 몬테카를로 추정량이 들어 있었다. 2010년대에는 딥러닝이 시맨틱 해싱, 의사 카운팅(pseudocounting), 상각 탐색(amortized search) 같은 더 흥미로운 기본 단위를 열어줬다. GPT-2와 GPT-3가 등장하면서 “자연어 이해”라는 새로운 컴퓨터 과학 기본 단위가 생겨났고, 문제를 직접 풀어야 하는 대신 원하는 것을 “그냥 물어보면” 되게 되었다.
추론 모델과 함께, 컴퓨터 과학에서는 더 많은 알고리즘적 잠금 해제가 일어날 것이다. 예를 들어, 고전적인 RL의 탐색 대 활용 트레이드오프는 상한 신뢰 구간(UCB), 톰슨 샘플링, 어드밴티지 추정의 베이스라인, 보수적 Q 추정, 최대 엔트로피 RL 같은 알고리즘들로 꽤 일반적으로 다뤄져 왔다. 이 알고리즘들의 상당수는 MDP 위에서 정의되는데, MDP는 우리가 알고리즘을 생각할 수 있도록 경직되고 저수준인 작업 공간을 고정해 준다. 환경에서 흥미로운 부분을 방문한다는 것이 무엇을 의미하는지 정의할 계산 도구가 없었기 때문에, “누적 정책 엔트로피 H(a|s)” 같은 근사적 목표를 만들어 쉽게 계산하고 연역적 논리로 엮어 쓸모 있는 것을 만들었던 것이다.
알고리즘을 구성하는 방식에 대한 이런 근본적인 가정들을 이제 다시 돌아볼 수 있다. 실제로 상태 엔트로피 H(s)는 물론 비디오-행동 정책에 대한 궤적 엔트로피 H(τ)도 근사할 수 있게 되었다. 베이지안 믿음 네트워크와 AlphaGo는 그래프에서 한 번에 간선 하나씩 순회해야 했지만, 이제는 명시적인 존재론적 자료 구조 없이도 LLM에게 당면한 특정 문제에 대해 훨씬 총체적으로 사고하도록 요청할 수 있다. 오늘날 완전히 새로운 RL 방법이 있는데, 그것은 그냥 LLM에게 “지금까지 시도한 모든 것을 생각해 보고, 아직 안 해본 것을 시도하라”고 말하는 것이다.
이렇게 강력한 빌딩 블록으로 또 어떤 알고리즘이 가능해질까? 당신이 어떤 회사의 팀 리드나 CTO라면, 이런 파일을 보고도 소프트웨어 엔지니어링과 컴퓨터 시스템이 2026년에 완전히 달라지리라는 확신이 들지 않을 수 있겠는가?
조언
이 글을 마무리하며, 나처럼 코딩 에이전트의 발전 속도에 정신을 못 차리고 그 의미를 곱씹고 있을 기술자들에게 실용적인 조언을 몇 가지 남기고 싶다.
소프트웨어 조직: 온갖 디지털 결과물을 척척 만들어내는 천재 군단을 활용할 수 있게 팀의 모노레포가 세팅되어 있지 않다면, 지금 당장 바꿔야 한다.
연구자: 자동화된 연구가 새로운 메타다. 에이전트 팀에게 목표를 지시하고, 풀스택 범위에서 어디에 집중해야 할지 판단할 줄 아는 사람은, 소프트웨어 만드는 일이 다시 즐거워질 만큼 짜릿한 생산성을 맛보게 될 것이다.
로보티시스트: 시뮬레이션 데이터에 얼마나 의존하고 실제 데이터에 얼마나 의존해야 하느냐는 오래된 질문이 있다. 자동화된 추론의 발전은 이전에 본 적 없는 수준으로 그 균형을 뒤흔들고 있다.
나는 이제 AI 2027과 Situational Awareness의 전망이 그럴듯하다고 본다. 솔직히 말하면 실현될 가능성이 높다고까지 생각한다.
